數據科學平臺是面向數據存儲、數據獲取、模型訓練、模型部署以及結果預測一體化的一款大數據挖掘產品,該平臺能夠通過對大規模數據集的處理,提高數據處理效率,依據機器學習、深度學習模型進行模型訓練,幫助用戶提供準實時的建模能力,當面對數據碎片化和數據隔離時,通過加密機制下的參數交換方式建立虛擬的共有模型,在充分保障各個參與方的隱私信息和數據安全的同時,多方聯合建模滿足對特定的業務場景數據分析的需求。
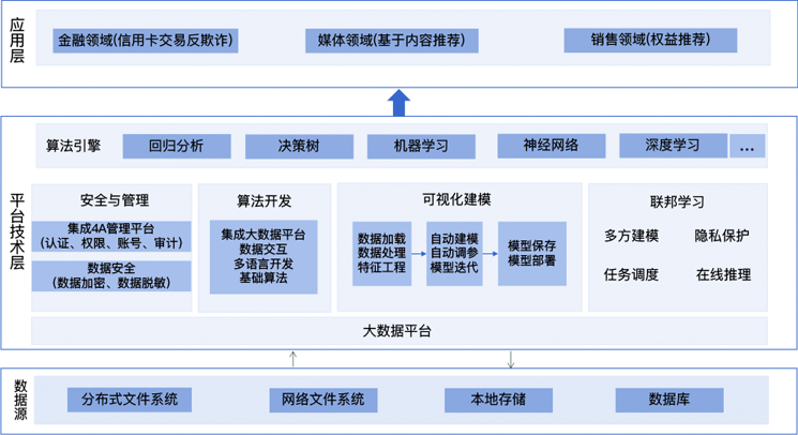
基于Hadoop分布式文件系統,有效處理超大規模數據集,具有穩定性高、可擴展性強的特點,并結合spark框架進行分布式數據預處理和算法實現,提供準實時的建模能力。
內置多種算法模型,可在頁面進行點擊操作完成數據處理、算法選擇,通過對模型的調用輸入參數的配置,實現模型訓練。
通過準確率、召回率等指標來評價算法的效果;通過參數優化、算法調整等方式改進模型效果。
內置聯邦學習,支持同態加密、SecretShare、DiffieHellman等多方安全計算協議,法律合規認證,大幅降低數據合作壁壘。
在聯合建模過程中,各個參與方依據貢獻度獲取建模收益,對惡意參與方的數據和模型作弊行為可檢測可抵御。
數據科學平臺用戶登陸使用LDAP用戶登陸,基于LDAP可作為數據庫的特點,通過目錄結構的方式存儲用戶信息來響應用戶查找需求。
通過對PySpark與Scala內核的安裝,實現啟動內核環境時自動接入大數據平臺,使用集群資源。
數據科學平臺支持常用的Python,R,Scala編程語言,通過在頁面上點擊新建可實現指定語言的使用。
在建模的同時,終端用戶可視化和度量模型訓練的全過程,支持對模型訓練過程全流程的跟蹤、統計和監控等,提供模型運行狀態、模型輸出和日志等信息。
平臺支持邏輯回歸、線性回歸、k-means、PCA、SVM等模型,支持神經網絡訓練,無監督學習,通過參數的調優實現模型最優化。
人工智能Pipeline調度平臺致力于完成高彈性、高性能的學習任務,主要包括模型訓練、模型管理、生產發布以及聯邦建模過程中輸入輸出實時跟蹤等。
解決代碼中的依賴模塊缺失問題,可在平臺提供的頁面進行命令行安裝以及自定義編程函數式安裝。
提供Kaggle比賽機器學習項目案例,提供樣例數據。

關注我們
Copyright ? 2018 | All rights by Everbright Technology CO.LTD 光大科技有限公司 京ICP備19005201號 京公網安備 11010702001841號 

請使用IE8及以上內核瀏覽器,建議使用Chrome、Firefox、360最新版等














